
[IaC]Terraform 사용하기 with AWS #02
Terraform을 통해 AWS 리소스를 생성하는 방법에 대해 포스팅하였습니다.
AWS VPC
Amazon VPC는 Amazon에서 제공하는 Private한 네크워크 망입니다. 다음은 VPC의 핵심 구성요소입니다.
- Virtual Private Cloud(VPC) - AWS에서 제공되는 가상의 프라이빗 클라우드.
- Subnet - VPC의 IP 주소 범위.
- Routing Table - 네트워크 트래픽을 전달할 위치를 결정하는 데 사용되는 라우팅 규칙.
- Internet Gateway - VPC의 리소스의 인터넷 통신을 위해 VPC에 연결하는 게이트웨이.
- NAT Gateway - 네트워크 주소 변환을 통해 프라이빗 서브넷에서 인터넷 또는 기타 AWS 서비스에 연결하는 게이트웨이.
- Security Group - 보안 그룹은 인스턴스에 대한 인바운드 및 아웃바운드 트래픽을 제어하는 가상의 방화벽.
- VPC Endpoint - 인터넷 게이트웨이, NAT 디바이스, VPN 연결 또는 AWS Direct Connect 연결을 필요로 하지 않고 PrivateLink 구동 지원 AWS 서비스 및 VPC 엔드포인트 서비스에 VPC를 비공개로 연결할 수 있습니다. VPC의 인스턴스는 서비스의 리소스와 통신하는 데 퍼블릭 IP 주소를 필요로 하지 않습니다. VPC와 기타 서비스 간의 트래픽은 Amazon 네트워크를 벗어나지 않습니다.
VPC 생성
provider "aws" {
region = "ap-northeast-2"
}
# vpc 생성
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
tags = {
Name = "terraform-01"
}
}
# public 서브넷 생성
resource "aws_subnet" "public_subnet" {
vpc_id = aws_vpc.main.id
cidr_block = "10.0.0.0/24"
availability_zone = "ap-northeast-2a"
tags = {
Name = "terraform-01-public_subnet"
}
}
# private 서브넷 생성
resource "aws_subnet" "private_subnet" {
vpc_id = aws_vpc.main.id
cidr_block = "10.0.10.0/24"
tags = {
Name = "terraform-01-private_subnet"
}
}
# igw 생성.
resource "aws_internet_gateway" "igw" {
vpc_id = aws_vpc.main.id
tags = {
Name = "terrafrom-igw"
}
}
# eip 생성
resource "aws_eip" "nat" {
vpc = true
lifecycle {
create_before_destroy = true
}
}
# nat gateway 생성
resource "aws_nat_gateway" "nat_gateway" {
allocation_id = aws_eip.nat.id
# Private subnet이 아니라 public subnet을 연결해야 한다.
subnet_id = aws_subnet.public_subnet.id
tags = {
Name = "NAT-GW"
}
}
# public route table 생성
resource "aws_route_table" "public" {
vpc_id = aws_vpc.main.id
# route rule을 table 안에 명시 한 경우.
route {
cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.igw.id
}
tags = {
Name = "route-table-public"
}
}
# subnet 연결
resource "aws_route_table_association" "route_table_association_public" {
subnet_id = aws_subnet.public_subnet.id
route_table_id = aws_route_table.public.id
}
# private route table 생성
resource "aws_route_table" "private" {
vpc_id = aws_vpc.main.id
tags = {
Name = "route-table-private"
}
}
# subnet 연결
resource "aws_route_table_association" "route_table_association_private" {
subnet_id = aws_subnet.private_subnet.id
route_table_id = aws_route_table.private.id
}
# route rule을 외부에 명시한 경우. 코드의 확장성을 위해선 아래와 같이 명시해주는게 좋음.
resource "aws_route" "private_nat" {
route_table_id = aws_route_table.private.id
destination_cidr_block = "0.0.0.0/0"
nat_gateway_id = aws_nat_gateway.nat_gateway.id
}
AWS S3
Amazon Simple Storage Service는 인터넷용 스토리지 서비스입니다. 이 서비스는 개발자가 더 쉽게 웹 규모 컴퓨팅 작업을 수행할 수 있도록 설계되었습니다.
Amazon S3에서 제공하는 단순한 웹 서비스 인터페이스를 사용하여 웹에서 언제 어디서나 원하는 양의 데이터를 저장하고 검색할 수 있습니다. 또한 개발자는 AWS 자체 웹 사이트의 글로벌 네트워크 운영에 사용하는 것과 같은 높은 확장성과 신뢰성을 갖춘 빠르고 경제적인 데이터 스토리지 인프라에 액세스할 수 있습니다. 이 서비스의 목적은 규모의 이점을 극대화하고 개발자들에게 이러한 이점을 제공하는 것입니다
S3 사용의 장점
Amazon S3는 의도적으로 단순성 및 견고성에 초점을 두는 최소한의 기능 세트를 사용하여 구축되었습니다. 다음은 Amazon S3을 사용할 때의 일부 장점입니다.
- 버킷 만들기 – 데이터를 저장하는 버킷을 만들고 해당 버킷의 이름을 지정합니다. 버킷은 데이터 스토리지를 위한 Amazon S3의 기본 컨테이너입니다.
- 데이터 저장 – 버킷에 데이터를 무한정으로 저장합니다. Amazon S3 버킷에 객체를 원하는 만큼 업로드할 수 있으며, 각 객체에 최대 5TB의 데이터를 포함할 수 있습니다. 각 객체는 고유한 개발자 할당 키를 사용하여 저장 및 검색합니다.
- 데이터 다운로드 – 데이터를 직접 다운로드하거나 다른 사람이 다운로드할 수 있도록 합니다. 언제든지 데이터를 직접 다운로드하거나 다른 사람이 다운로드하도록 허용할 수 있습니다.
- 권한 – 데이터를 Amazon S3 버킷으로 업로드 또는 다운로드하려는 사용자에게 액세스 권한을 부여하거나 해당 권한을 거부합니다. 3가지 유형의 사용자에게 업로드 및 다운로드 권한을 부여할 수 있습니다. 인증 메커니즘을 사용하면 데이터가 무단으로 액세스되지 않도록 보호하는 데 도움이 될 수 있습니다.
- 표준 인터페이스 – 모든 인터넷 개발 도구 키트에서 사용할 수 있도록 설계된 표준 기반 REST 및 SOAP 인터페이스를 사용합니다.
AWS S3 개념
Buckets
버킷은 Amazon S3에 저장된 객체에 대한 컨테이너입니다. 모든 객체는 어떤 버킷에 포함됩니다. 예를 들어 photos/puppy.jpg로 명명된 객체는 미국 서부(오레곤) 리전의 awsexamplebucket1 버킷에 저장되며 URL [https://awsexamplebucket1.s3.us-west-2.amazonaws.com/photos/puppy.jpg](https://awsexamplebucket1.s3.us-west-2.amazonaws.com/photos/puppy.jpg)를 사용하여 주소를 지정할 수 있습니다.
버킷은 다음과 같은 여러 가지 용도로 사용됩니다.
- Amazon S3 네임스페이스를 최상위 수준으로 구성합니다.
- 스토리지 및 데이터 전송 요금을 담당하는 계정을 식별합니다.
- 액세스 제어에 사용됩니다.
- 사용량 보고를 위한 집계 단위로 사용됩니다.
특정 AWS 리전에서 생성되도록 버킷을 구성할 수 있습니다. 객체가 추가될 때마다 Amazon S3에서 고유한 버전 ID를 생성하고 이를 객체에 할당하도록 버킷을 구성할 수도 있습니다. 자
Objects
객체는 Amazon S3에 저장되는 기본 개체입니다. 객체는 객체 데이터와 메타데이터로 구성됩니다. 데이터 부분은 Amazon S3에서 볼 수 없습니다. 메타데이터는 객체를 설명하는 이름-값 페어의 집합입니다. 여기에는 마지막으로 수정한 날짜와 같은 몇 가지 기본 메타데이터 및 Content-Type 같은 표준 HTTP 메타데이터가 포함됩니다. 객체를 저장할 때 사용자 정의 메타데이터를 지정할 수도 있습니다.
객체는 키(이름) 및 버전 ID를 통해 버킷 내에서 고유하게 식별됩니다.
Keys
키는 버킷 내 객체의 고유한 식별자입니다. 버킷 내 모든 객체는 정확히 하나의 키를 갖습니다. 버킷, 키 및 버전 ID의 조합은 각 객체를 고유하게 식별합니다. 따라서 Amazon S3을 “버킷 + 키 + 버전”과 객체 자체 사이의 기본 데이터 맵으로 생각할 수 있습니다. Amazon S3 내 모든 객체는 웹 서비스 엔드포인트, 버킷 이름, 키, 그리고 선택 사항인 버전의 조합을 통해 고유하게 주소를 지정할 수 있습니다. 예를 들어, [https://doc.s3.amazonaws.com/2006-03-01/AmazonS3.wsdl](https://doc.s3.amazonaws.com/2006-03-01/AmazonS3.wsdl)이라는 URL에서 “doc“는 버킷의 이름이고 “2006-03-01/AmazonS3.wsdl“은 키입니다.
Regions
Amazon S3에서 사용자가 만드는 버킷을 저장할 지리적 AWS 리전을 선택할 수 있습니다. 지연 시간 최적화, 비용 최소화, 규정 요구 사항 준수 등 다양한 필요에 따라 리전을 선택할 수 있습니다. 특정 리전에 저장된 객체는 사용자가 명시적으로 객체를 다른 리전으로 전송하지 않는 한 해당 리전을 벗어나지 않습니다. 예를 들어 유럽(아일랜드) 리전에 저장된 객체는 해당 리전을 벗어나지 않습니다.
AWS S3 스토리지 클래스
1. 자주 액세스하는 객체를 위한 스토리지 클래스
성능에 민감한 사용 사례(밀리초 액세스 시간을 필요로 하는 사례)와 자주 액세스되는 데이터를 위해 Amazon S3는 다음과 같은 스토리지 클래스를 제공합니다.
- S3 Standard — 기본 스토리지 클래스입니다. 객체를 업로드할 때 스토리지 클래스를 지정하지 않으면 Amazon S3가 S3 Standard 스토리지 클래스를 할당합니다.
- Reduced Redundancy — RRS(Reduced Redundancy Storage) 스토리지 클래스는 S3 Standard 스토리지 클래스보다 더 적은 중복성으로 저장될 수 있으며 중요하지 않고 재현 가능한 데이터용으로 설계되었습니다.
2. 자주 액세스하는 객체와 자주 액세스하지 않는 객체를 자동으로 최적화하는 스토리지 클래스
S3 Intelligent-Tiering 스토리지 클래스는 성능 영향 또는 운영 오버헤드 없이 가장 비용 효율적인 스토리지 액세스 계층으로 데이터를 자동으로 이동하여 스토리지 비용을 최적화하도록 설계되었습니다. S3 Intelligent-Tiering은 액세스 패턴이 변경될 때 자주 액세스하는 계층과 저렴한 비용의 자주 액세스하지 않는 계층 간에 세분화된 객체 수준의 데이터를 이동함으로써 자동 비용 절감 효과를 제공합니다. Intelligent-Tiering 스토리지 클래스는 액세스 패턴을 알 수 없거나 예측할 수 없어 수명이 긴 데이터에 대해 스토리지 비용을 자동으로 최적화하려는 경우 이상적입니다.
S3 Intelligent-Tiering 스토리지 클래스는 두 액세스 계층에 객체를 저장합니다. 한 계층은 자주 액세스하는 데이터에 최적화되어 있으며 비용이 저렴한 다른 계층은 자주 액세스하지 않는 데이터에 최적화되어 있습니다. Amazon S3는 객체당 소액의 월별 모니터링 및 자동화 요금으로 S3 Intelligent-Tiering 스토리지 클래스에서 객체의 액세스 패턴을 모니터링하고 연속 30일 동안 액세스하지 않은 객체를 자주 액세스하지 않는 액세스 계층으로 이동합니다.
S3 Intelligent-Tiering 스토리지 클래스를 사용할 때 검색 요금은 없습니다. 빈번하지 않은 액세스 계층의 객체에 액세스하면 이 객체는 자동으로 빈번한 액세스 계층으로 다시 이동합니다. 객체가 S3 Intelligent-Tiering 스토리지 클래스 내 액세스 계층 간에 이동될 때는 계층화 요금이 추가로 적용되지 않습니다.
3. 자주 액세스하지 않는 객체를 위한 스토리지 클래스
S3 Standard_IA 및 S3 One Zone-IA 스토리지 클래스는 수명이 길고 자주 액세스하지 않는 데이터용으로 설계되었습니다. 여기서 IA는 *자주 액세스하지 않음*을 의미합니다. S3 Standard-IA 및 S3 One Zone-IA 객체는 밀리초 액세스에 사용 가능합니다(S3 Standard 스토리지 클래스와 동일함). Amazon S3는 이러한 객체에 대한 검색 요금을 부과하므로 이러한 객체는 자주 액세스되지 않는 데이터에 가장 적합합니다.
예를 들어, S3 Standard-IA 및 S3 One Zone-IA 스토리지 클래스를 선택할 수 있습니다.
- 백업을 저장하는 경우.
- 자주 액세스되지는 않지만 그래도 밀리초 액세스가 필요한 오래된 데이터의 경우. 예를 들어, 데이터를 업로드할 때 S3 Standard 스토리지 클래스를 선택하고 수명 주기 구성을 사용하여 Amazon S3에 객체를 S3 Standard-IA 또는 S3 One Zone-IA 클래스로 전환하도록 지시할 수 있습니다.
이들 스토리지 클래스는 다음과 같은 차이가 있습니다.
- S3 Standard-IA — Amazon S3가 객체 데이터를 지리적으로 분리된 여러 개의 가용 영역에 중복 저장합니다(S3 Standard 스토리지 클래스와 유사함). S3 Standard-IA 객체는 가용 영역의 손실에 대한 복원성이 있습니다. 이 스토리지 클래스는 S3 One Zone-IA 클래스보다 뛰어난 가용성 및 복원성을 제공합니다.
- S3 One Zone-IA — Amazon S3가 객체 데이터를 한 개의 가용 영역에만 저장하므로 S3 Standard-IA보다 비용이 더 저렴합니다. 그러나 데이터는 지진 및 홍수와 같은 재해에 의한 가용 영역의 물리적 손실에 대해서는 복원성이 없습니다. S3 One Zone-IA 스토리지 클래스는 Standard-IA만큼 내구성이 있지만 가용성과 복원성은 더 낮습니다. *
다음과 같이 하는 것이 좋습니다.
- S3 Standard-IA — 기본 데이터나 다시 생성할 수 없는 데이터의 복사본에만 사용합니다.
- S3 One Zone-IA — 가용 영역에 장애 발생 시 데이터를 다시 생성할 수 있는 경우, 그리고 S3 교차 리전 복제(CRR)를 설정하는 경우 객체 복제본에 사용합니다.
4. 객체 아카이빙을 위한 스토리지 클래스
S3 Glacier 및 S3 Glacier Deep Archive 스토리지 클래스는 저비용 데이터 아카이빙을 위해 설계되었습니다. 이러한 스토리지 클래스는 S3 Standard 스토리지 클래스와 동일한 내구성과 복원성을 제공합니다.
이들 스토리지 클래스는 다음과 같은 차이가 있습니다.
- S3 Glacier—분 단위로 데이터의 일부를 검색해야 하는 아카이브에 사용합니다. S3 Glacier 스토리지 클래스에 저장된 데이터는 최소 스토리지 기간이 90일이며 신속 검색을 사용하여 최소 1~5분 이내에 액세스할 수 있습니다. 90일 최소 기간 이전에 삭제했거나 덮어썼거나 다른 스토리지 클래스로 이전한 경우, 90일 요금이 부과됩니다.
- S3 Glacier Deep Archive—거의 액세스할 필요가 없는 데이터를 보관할 때 사용합니다. S3 Glacier Deep Archive 스토리지 클래스에 저장된 데이터의 최소 스토리지 기간은 180일이고 기본 검색 시간은 12시간입니다. 180일 최소 기간 이전에 삭제했거나 덮어썼거나 다른 스토리지 클래스로 이전한 경우, 180일 요금이 부과됩니다. S3 Glacier Deep Archive는 AWS에서 가장 저렴한 스토리지 옵션입니다. S3 Glacier Deep Archive에 대한 스토리지 비용은 S3 Glacier 스토리지 클래스를 사용하는 것보다 저렴합니다. 48시간 이내에 데이터를 반환하는 대량 검색을 사용하여 S3 Glacier Deep Archive 검색 비용을 절감할 수 있습니다.
S3 Bucket 생성
provider "aws" {
region = "ap-northeast-2"
}
resource "aws_s3_bucket" "main" {
bucket = "freey-s3-01"
tags = {
Name = "freey-s3-01"
# 버킷 네임은 고유한 이름이어야 한다.
}
}
- apply 후, 아래와 같이 파일을 cp 할수 있다.
vim index.html
test
~ aws s3 cp index.html s3://freey-s3-01/
upload: ./index.html to s3://freey-s3-01/index.html
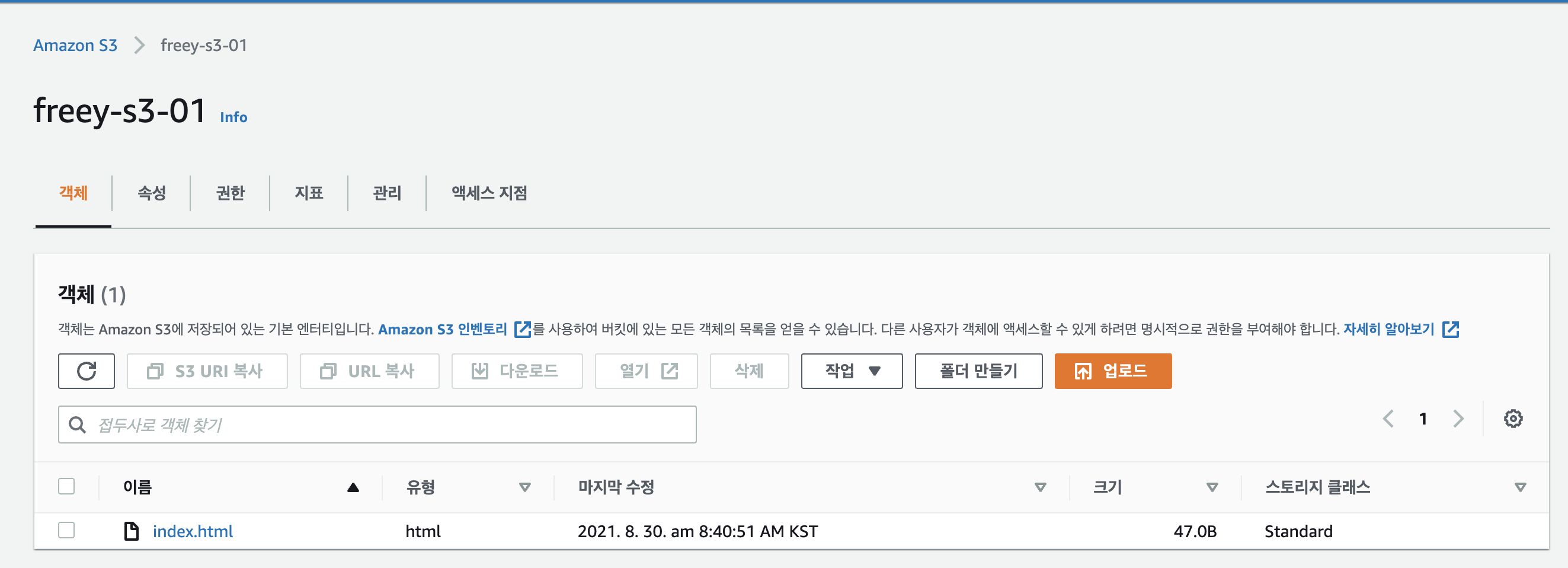
- 반대로 다운로드도 할 수 있다.
~ aws s3 cp s3://freey-s3-01/index.html ./test.html
download: s3://freey-s3-01/index.html to ./test.html
- AWS 콘솔에서 index.html을 모든 사용자에 대해 권한을 주게 되면 웹에서 사용 가능하다.
- https://freey-s3-01.s3.ap-northeast-2.amazonaws.com/index.html
- 즉, S3는 static 파일에 대한 웹 서버 용도로도 사용이 가능하다.
AWS IAM
AWS Identity and Access Management(IAM)는 AWS 리소스에 대한 액세스를 안전하게 제어할 수 있는 웹 서비스입니다. IAM을 사용하여 AWS기본 접근 및 리소스를 사용하도록 권한 부여를 할 수 있습니다.
- AWS IAM User — AWS IAM User는 AWS 내에서 생성하는 사용자로 AWS와 상호작용하는 사용자 혹은 어플리케이션을 의미합니다.
- AWS IAM Group — AWS IAM Group은 IAM User의 집합이고, Group을 사용함으로써 다수 사용자에 대하여 동일한 권한을 보다 쉽게 관리할 수 있습니다.
- AWS IAM Role — AWS IAM Role은 특정 권한을 가진 IAM 자격증명입니다. 이 Role을 사용함으로써 특정 사용자 혹은 어플리케이션에 혹은 AWS 서비스에 접근 권한을 위임할 수 있습니다.
- AWS IAM Policy — AWS의 접근하는 해당 권한을 정의하는 개체로 AWS IAM 리소스들과 연결하여 사용할 수 있습니다.
IAM USER 생성
provider "aws" {
region = "ap-northeast-2"
}
- iam_gildong_hong.tf
resource "aws_iam_user" "gildong_hong" {
name = "gildong.hong" }
위 코드로 생성한 유저는 패스워드 설정이 되어있지 않기 때문에 콘솔 접속은 불가능하다.
콘솔을 통해 직접 패스워드를 생성하거나, AWS CLI 등을 통해 설정해야 한다.
AWS GROUP 생성
resource "aws_iam_group" "devops_group" {
name = "devops"
}
- devops_group.tf
resource "aws_iam_group_membership" "devops" {
name = aws_iam_group.devops_group.name
users = [
aws_iam_user.gildong_hong.name
]
group = aws_iam_group.devops_group.name
}
AWS ROLE 생성
- iam_role.tf
resource "aws_iam_role" "hello" {
name = "hello-iam-role"
path = "/"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": "ec2.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
}
resource "aws_iam_role_policy" "hello_s3" {
name = "hello-s3-download"
role = aws_iam_role.hello.id
policy = <<EOF
{
"Statement": [
{
"Sid": "AllowAppArtifactsReadAccess",
"Action": [
"s3:GetObject"
],
"Resource": [
"*"
],
"Effect": "Allow"
}
]
}
EOF
}
resource "aws_iam_instance_profile" "hello" {
name = "hello-profile"
role = aws_iam_role.hello.name
}
AWS IAM Policy 의 종류
AWS의 접근하는 해당 권한을 정의하는 개체로 AWS IAM 리소스들과 연결하여 사용할 수 있습니다. 즉 AWS IAM policy 는 user 에 할당 할 수 도, group 에 할당 할 수 있습니다. IAM policy 는 여러 타입으로 나누어져있습니다.
AWS Managed policy: AWS에서 먼저 생성해놓은 Policy set 입니다. 사용자가 권한(Permission)을 변경할 수 없습니다.
Customer Managed policy: User 가 직접 생성하는 Policy 로 권한을 직접 상세하게 만들어 관리할 수 있습니다.
IAM user policy 생성
resource "aws_iam_user" "gildong_hong" {
name = "gildong.hong"
}
resource "aws_iam_user_policy" "art_devops_black" {
name = "super-admin"
user = aws_iam_user.gildong_hong.name
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"*"
],
"Resource": [
"*"
]
}
]
}
EOF
}
댓글남기기